While going through the latest lab upgrade round, I found myself running into an error when upgrading NSX. The NSX Edge Transport Nodes (ETN) upgrade successfully, however, the NSX Host Transport Nodes (HTN) portion fails.
p
info
Not that the solutions is so special but it had me running around a bit, therefore I wanted to share.
The upgrade returns the following error:
A general system error occurred: Image is not valid. Component NSX LCP Bundle(NSX LCP Bundle(4.1.0.2.0-8.0.21761693)) has unmet dependency nsx-python-greenlet-esxio because providing component(s) NSX LCP Bundle(NSX LCP Bundle(4.1.0.2.0-8.0.21761693)) are obsoleted.
At the same time the same error is listed on vCenter:
Wile not exactly mentioning the solution, it got me thinking it could be similar. The procedure instructs to download, and work with the JSON export of the vLCM configuration:
vLCM json
Default
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"add_on":{
"name":"DEL-ESXi",
"version":"802.22380479-A04"
},
"alternative_images":null,
"base_image":{
"version":"8.0.2-0.40.23825572"
},
"components":{
"Intel-i40en":"2.5.11.0-1OEM.700.1.0.15843807",
"Synology-syno-nfs-vaai-plugin":"2.0-1109",
"nsx-lcp-bundle":"4.1.0.2.0-8.0.21761693"
},
"hardware_support":null,
"removed_components":null,
"solutions":null
}
I removed the highlighted nsx-lcp-bundle line, saved and imported the JSON again to vLCM. Hereafter I retried the upgrade on NSX and could progress now!
Deleting the datastore where a content library is hosted is probably not the best idea but … yes stupid error and now what. If you are not faint of heart (and now how to take a snapshot), you can rectify this. You should contact GSS as there is not documented solution and this might break.
Take a snapshot and verify if the vCenter backups are in a healthy status. Yes? Ok go ahead.
Log on to the vCenter and create a new Content Library and name it ‘i-made-an-error’. Use the new datastore you want to use and keep the rest of the settings default as these don’t really matter.
Open an SSH session to the vCenter and connect to the Postgress DB ‘VCDB’
Connect to the vCenter database
PgSQL
1
psql-dVCDB-Upostgres
To show which tables are present within the database:
Show all tables in the database
PgSQL
1
\d
Show an overview of the Content Libraries added ( make sure to add the trailing ;):
Show all the Content Libraries
PgSQL
1
SELECTid,nameFROMcl_library;
Now that we have an overview of the Content Libraries, with the one that is throwing an error highlighted.
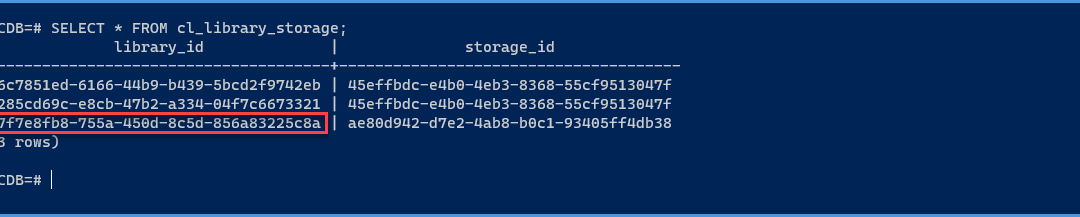
In the following overview we find the library id from the new Content Library we just added and also the corresponding storage id.
Show all the Content Libraries and their storage
PgSQL
1
SELECT*FROMcl_library_storage;
I will update the storage id from the faulty one we found on the previous screenshot with the one we found for the new Content Library.
Update the storage id from the faulty Content Library
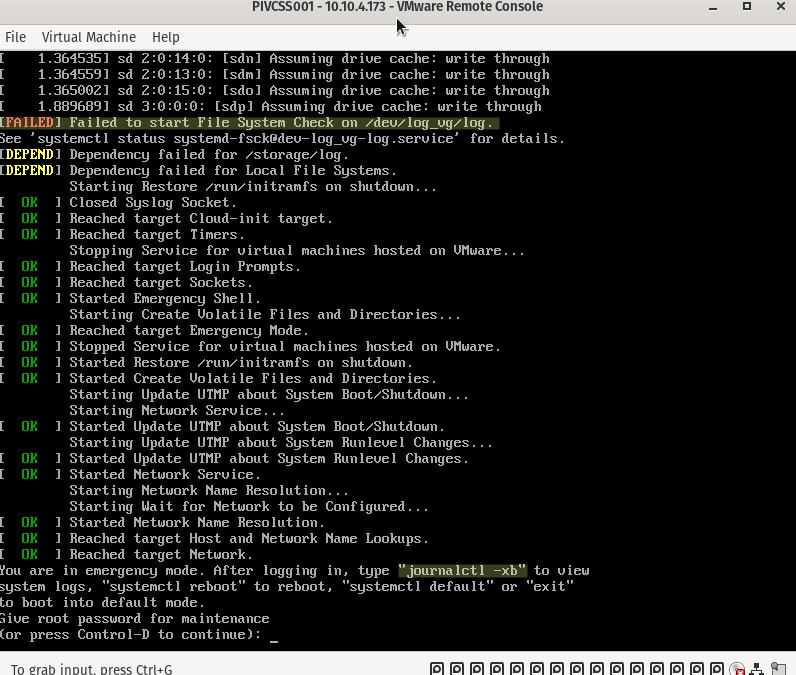
Due to a power failure of the storage where the vCenter Server Appliance resides, the VCSA does not boot. Connecting to the console shows the following output:
When you see this screen, none of the services are started as the appliance does not fully start. This implies that there is no means of connecting to the H5 client nor the VAMI interface on port 5480.
Why does the VCSA not boot and where do I start troubleshooting?
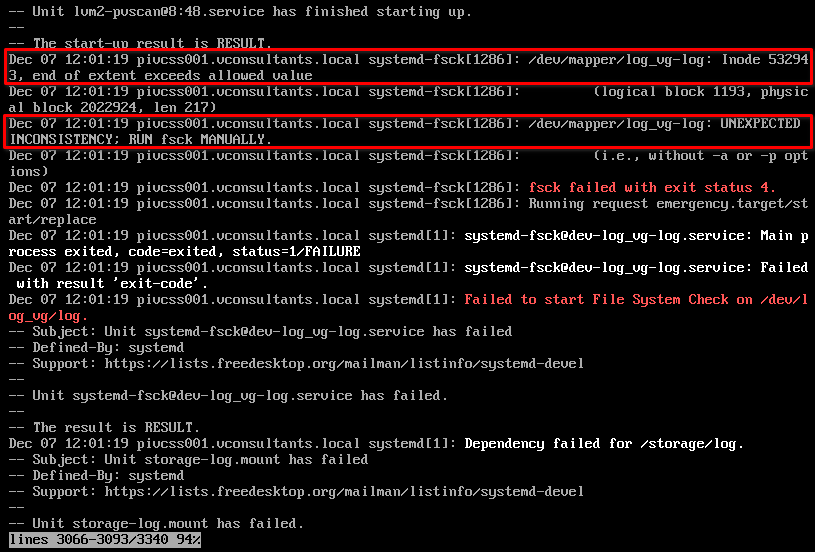
There are two important things to mentioned on the screenshot above, this is where we start:
Failed to start File System Check on /dev/log_vg/log
journalctl -xb
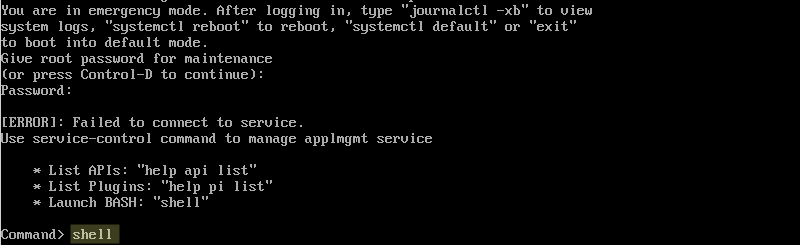
First we take a look at ‘journalctl -xb’. To do this we need to supply the root password and launch the BASH:
Now that have shell access we can take a look at ‘journalctl -xb’:
Shell
1
journalctl-xb
Type G to go to the bottom of the log file:
Shell
1
G
journalctl -xb
Work upwards, the most relevant logs will be at the bottom. For the sake of this blog post, I have type -S. This will turn on/off word wrap, in this case, I turned on word wrap.
File System Check
Going up a little I find these entries:
There is a problem with a certain inode and File System Check (fsck) should be run. Let’s see how we can do that. Is it as simple as running:
Shell
1
fsck/dev/mapper/log_vg-log
It seems like it. Running the above command finds some errors and suggests to repair. I confirmed.
Other volumes
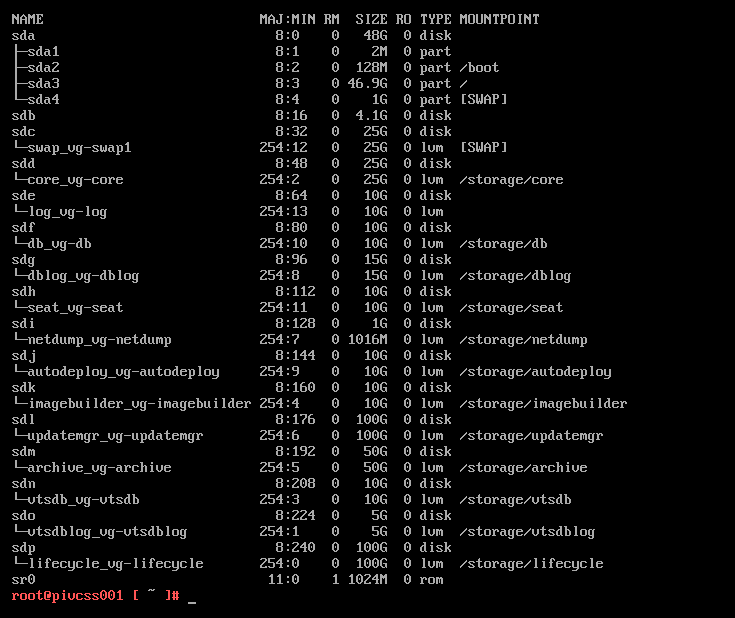
Let’s check the other logical volumes (lvm). First we will run ‘lsblk’ to take a look at the drive layout:
Shell
1
lsblk
Remark: When we take a look at the type, we see the disks, eg. sda, sdb, etc… The difference between sda and the rest is that sda is partitioned with standard partitions and on the rest the disks an LVM has been created.
I checked all other volumes and found none of them were having issues.
Reboot
To reboot while you are in maintenance boot:
Default
1
reboot--force
After the reboot, I could connect to the H5 client and clear the relevant errors.
Remark
This blog post is very similar to this one here. Although they are very much alike, the issues in the older blog post were on a standard partition on a VCSA 6.5 whereas the issues described and addressed in this post are on a VCSA 7.0 LVM physical volume.
So I changed the admin password ‘password-expiration’, not even bothering to open the event details. I just assumed this is about the admin user.
Shell
1
clearuser admin password-expiration
Done.
Not true. Some time later that day I found that the alarms were still open. I figured that this is some sort of timing issue, that the alarms were not automatically cleared yet. So I set them to resolved manually. Almost the same minute the alarms are triggered again, so no timing issue. If I only would have counted the alarms the first time it would have showed me that there more alarms than NSX-T components where I cleared the password expiration for the admin user.
It was only when I read the alarm in detail that I noticed the alarm is not the same one I saw before. This alarm was not triggered about the password expiration of the admin user but showed that it was for the audit user. The alarms are very much the same only the username is different, so easily overlooked.
So doing the math. Initially I had 8 open alarms, of which 3 were put to resolved automatically after changing the password expiration of the admin user. One on the NSX-T Manager and one on each of the 2 edge nodes. Which left 5 open alarms to take care of. Checking all the alarms gave me the following actions:
clear alarm for the root user on NSX-T Manager
clear alarms for the root user and the audit user on the NSX-T Edge 1 and 2
CAUTION
Password expiration should be part of your password policy strategy. Disabling the password expiration on a production system is not a good strategy.
I have been working on a script to deploy environments on a regular basis in my homelab. While I have made great progress I have not been able to get this completed due to the lack of time. It did up my powershell script writing skills.
A while ago I followed a webinar about VMware Cloud Foundation Lab Constructor (VLC in short). This will deploy a VCF environment in a decent amount of time. With little effort I have been able to get this up and running multiple times. There are some pitfalls I ran into. My goal is to get to learn more about VCF, NSX-T and K8s all in a VMware Validated Design (VVD) setup.
You can get access too by completing the registration form at tiny.cc/getVLC.
The following files are included in the download:
Example_DNS_Entries.txt
VCF Lab Constructor Install Guide 39.pdf
VLCGui.ps1
add_3_hosts.json
add_3_hosts_bulk_commission VSAN.json
default-vcf-ems.json
default_mgmt_hosthw.json
maradns-2.0.16-1.x86_64.rpm
mkisofs.exe
plink.exe
As I already have a DNS infrastructure in place I used ‘Example_DNS_Entries.txt‘ as a reference to create all the necessary DNS entries.
Read the documentation pdf FIRST. It will give you a good insight in what will be set up, won’t be set up and how everything will be set up. I’m not planning to repeat info that is included in the documentation. The only thing that I have copied from this pdf is the disclaimer because I feel it is important:
Below I have included the various configuration files and split them to show the different parts and also show where I deferred from the default. There are the configuration files that the VLC script will use:
Management domain:
default-vcf-ems.json → changed all ip addresses, gateways, hostnames, networks and licenses
default_mgmt_hosthw.json → changed the amount of CPUs (8 → 12), the amount of RAM (32 and 64 → 80) and the disk sizes(50,150 and 175 → 150)
Workload domain
add_3_hosts.json → changed the hostname, management IP and IP gateway
To deploy VCF and be able to deploy NSX-T you will need a good amount of resources. The mimimum of host resources to be able to deploy NSX-T is 12vCPUs (There is a workaround to lower the vCPU requirements for NSX-T) and 80GB of RAM due to the NSX-T requirements.
The configuration files
The first file is the ‘default_mgmt_hosthw.json’. This file describes the specs for the (virtual) hardware for the management domain hosts:
default management host hardware json
The second file is the ‘default-vcf-ems.json’. This file describes the configuration for all software components for the management domain:
default VCF EMS JSON
The last configuration file is ‘add_3_hosts.json’. This configuration file is optional and can be used to prepare three extra hosts for the first workload domain:
Add 3 host JSON
Where did I change the defaults
There are some settings that I changed from the defaults aside from changing the names and network settings:
in the ‘default_mgmt_hosthw.json’ I have changed the CPU to 12 to be able to deploy NSX-T
in the ‘default_mgmt_hosthw.json’ I have changed the RAM 80 to be able to deploy NSX-T
How do we start
If you are meeting the prerequirements it is fairly simple. Fire up the ‘VLCGui.ps1’. This will present the following gui which will give the ability to supply all the necessary information and to connect to your physical environment. It speaks for itself, just make sure the Cluster, Network Name and Datastore field are higlighted blue like the following.
What’s next
I hope to expand this inital post with a couple of follow-up posts. These are the topics that I’m currently thinking about: